
yoooniverse
[kaggle] Learn Tutorial_Pandas 정리_0 본문
https://www.kaggle.com/learn/pandas
Learn Pandas Tutorials
Solve short hands-on challenges to perfect your data manipulation skills.
www.kaggle.com
< 1 > Creating, Reading, and Writing
pandas: the most popular Python library for data analysis.
1 시작하기: 라이브러리 import 해주기
import pandas as pd2 Creating data
two core objects in pandas: the DataFrame & the Series
- DataFrame: table과 같은 개념. row와 column으로 구성됨
entry : 각 row, column 값에 해당하는 value를 지칭.
ex) “0, No” entry의 value : 131
각 entry에는 다양한 형태의 데이터가 들어갈 수 있다. integer, strings 등 모두 가능 - pd.DataFrame: constructor to generate these DataFrame objects
- dictionary의 개념처럼, key값은 column, value 값은 entry로 구성된다
- row 값은 자동으로 0번부터 순서가 매겨짐.원한다면row값역시특정label을매길수있다.
👉 The list of row labels used in a DataFrame is known as an Index
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'],
'Sue': ['Pretty good.', 'Bland.']})
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'],
'Sue': ['Pretty good.', 'Bland.']},
index = ['Product A', 'Product B'])- Series: a sequence of data values
DataFrame이 table이라면, Series는 list라고 할 수 있다.
DataFrame의 single column이 Series에 해당하는 것. 따라서 row에 label 값을 매길 수 있다.
DataFrame과의 차이 : column name이 존재하지 않는다. 그대신 series 하나에 대한 이름은 지정할 수 있음.
pd.Series([1, 2, 3, 4, 5])pd.Series([30, 35, 40],
index = ['2015 Sales', '2016 Sales', '2017 Sales'],
name = 'Product A')Series 여러 개를 한 데 모아놓은 것이 DataFrame이라고 생각하면 쉽다!
3 Reading
데이터 파일 중 가장 일반적인 형태는 csv 파일
CSV file: a table of values separated by commas Comma−SeparatedValues
튜토리얼에서는 wine_review csv 파일로 실습을 진행했다.
exercise부분에는살짝다른csv파일을사용.이는다른게시물에일괄정리예정
파일을 확인해본 결과 자체적으로 index 레이블이 존재하는 것을 알 수 있음.
이 레이블을 사용하기 위해 csv 파일을 읽어올 때 해당 레이블을 데이터의 index로 사용하도록 설정
wine_reviews = pd.read_csv('/content/drive/MyDrive/Kaggle/project0/winemag-data-130k-v2.csv')
wine_reviews = pd.read_csv('/content/drive/MyDrive/Kaggle/project0/winemag-data-130k-v2.csv',
index_col=0)
wine_reviews.head()+ Writing new csv file
animals = pd.DataFrame({'Cows': [12, 20], 'Goats': [22, 19]}, index=['Year 1', 'Year 2'])
animals.to_csv('cows_and_goats.csv')
animals< 2 > Indexing, Selecting & Assigning
Native accessors
파이썬 자체적으로 데이터프레임 인덱싱하는 방법을 제공한다.
👇 Two ways of selecting a specific Series out of a DataFrame
wine_reviews.country
wine_reviews['country']
# reviews['country'][0] 👈 single specific value
두 코드 모두 같은 결과를 보여줌
pandas도 인덱스, 레이블 차원의 두가지 데이터 접근 방법이 존재한다.
1 Indexing
Index-based selection: selecting data based on its numerical position in the data
▶️ "iloc"
ex) selecting the first row of data in a DF using 'iloc'
wine_reviews.iloc[0]
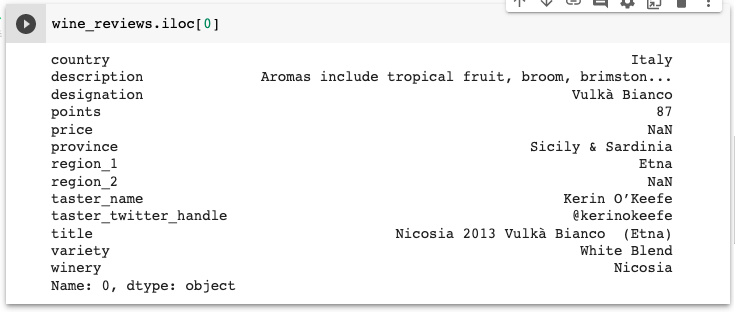
파이썬 내장 코드를 이용해 DataFrame에 접근할 때 column 기준으로 결과물이 나오는 반면,
loc와 iloc는 row 중심으로 DataFrame의 data를 가져온다.
(loc and iloc are row-first, column-second. This is the opposite of what we do in native Python, which is column-first, row-second.)
To get column based data, use iloc like this,
wine_revies.iloc[:, 0]' : ' operator means 'everything'
combined with other selectors, it can be used to indicate a range of values
ex) to select the 'country' column from just the first~third row
wine_reviews.iloc[:3, 0]
#more ways to select certain entries
wine_reviews.iloc[1:3, 0]
wine_reviews.iloc[[0, 1, 2], 0] #It's also possible to pass a list
wine_reviews.iloc[-5:] #the last five elements of the dataset.
Label-based selection: it's the data index value, not its position, which matters.
▶️ "loc"
ex) selecting the first row & 'country' column entry in a DF using 'loc'
wine_reviews.loc[0, 'country']kaggle에서 발췌한 설명
Choosing between loc and iloc¶
When choosing or transitioning between loc and iloc, there is one "gotcha" worth keeping in mind, which is that the two methods use slightly different indexing schemes.
iloc uses the Python stdlib indexing scheme, where the first element of the range is included and the last one excluded. So 0:10 will select entries 0,...,9. loc, meanwhile, indexes inclusively. So 0:10 will select entries 0,...,10.
Why the change? Remember that loc can index any stdlib type: strings, for example. If we have a DataFrame with index values Apples, ..., Potatoes, ..., and we want to select "all the alphabetical fruit choices between Apples and Potatoes", then it's a lot more convenient to index df.loc['Apples':'Potatoes'] than it is to index something like df.loc['Apples', 'Potatoet'] tcomingaftersinthealphabet.
This is particularly confusing when the DataFrame index is a simple numerical list, e.g. 0,...,1000. In this case df.iloc[0:1000] will return 1000 entries, while df.loc[0:1000] return 1001 of them! To get 1000 elements using loc, you will need to go one lower and ask for df.loc[0:999].
Otherwise, the semantics of using loc are the same as those for iloc.
Indexing, Selecting & Assigning
Explore and run machine learning code with Kaggle Notebooks | Using data from multiple data sources
www.kaggle.com
+) set_index 메소드: DataFrame내의 column의 label을 이용하여 index 설정을 할 수 있다.
wine_reviews.set_index("title")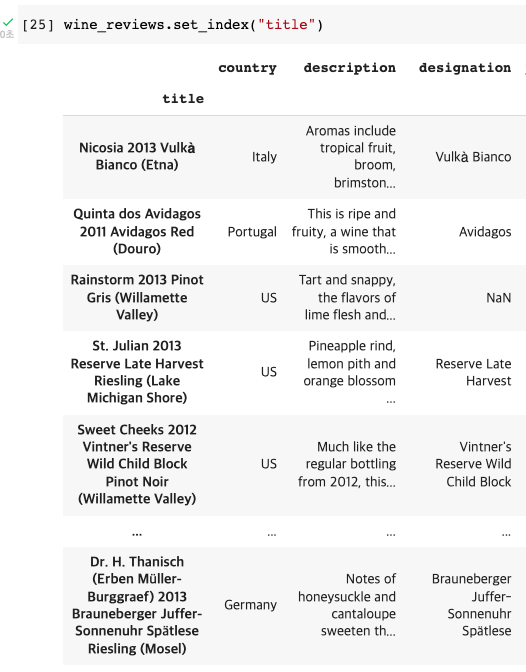
2 Selecting
Conditional selection
시나리오) we're interested specifically in better-than-average wines produced in Italy.
1단계) country 값이 Italy인 놈들 찾기
wine_reviews.country == 'Italy'
'''
0 True
1 False
2 False
3 False
4 False
...
129966 False
129967 False
129968 False
129969 False
129970 False
Name: country, Length: 129971, dtype: bool
'''True/False 유형bool으로 결과가 나오므로 이를 loc 함수에 응용할 수 있다
2단계) loc 함수에 1단계 내용을 조건문으로 넣는다!
👉 country column이 'Italy'인 데이터만 찾아서 넣어줘.
wine_reviews.loc[wine_reviews.country == 'Italy']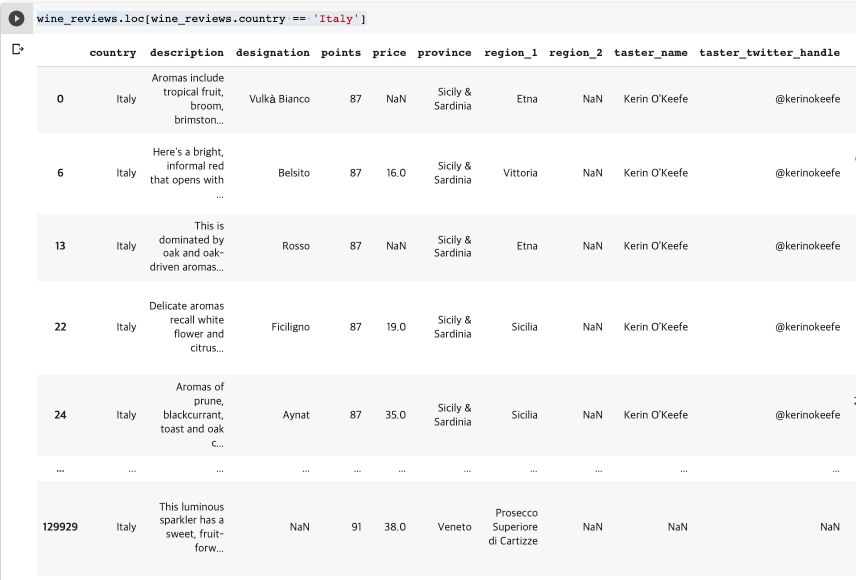
그 결과 130,000줄의 데이터 중 20,000여 줄이 뽑힌 것을 알 수 있음. 전체의 15% 정도가 이태리 와인인 것을 알 수 있다.
3단계) loc 함수에 조건을 추가한다
👉 country가 'Italy'이고, points가 90 이상인 데이터만 찾아서 보여줘. & 연산자 사용
그 결과 6,700여 줄이 뽑혔음
wine_reviews.loc[(wine_reviews.country == 'Italy') & (wine_reviews.points >= 90)]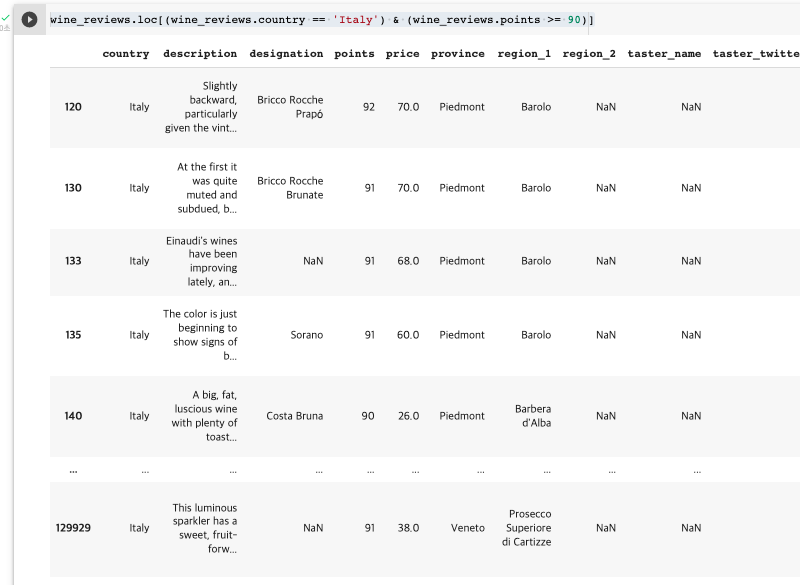
+) 다른 연산자를 사용한 조건문 설정도 가능하다.
이태리 와인이거나, 90점 이상이거나 |연산자사용
+) 판다스 내장 함수를 이용한 conditional selecting
① isin : select data whose value "is in" a list of values.
wine_reviews.country.isin(['Italy'])
wine_reviews.loc[wine_reviews.country.isin(['Italy'])]② isnull, notnull : highlight values which are orarenot empty (NaN).
wine_reviews.loc[wine_reviews.price.notnull()]3 Assigning
Assigning data
wine_reviews['critic'] = 'everyone'
wine_reviews['critic']
'''
0 everyone
1 everyone
...
129969 everyone
129970 everyone
Name: critic, Length: 129971, dtype: object
'''wine_reviews['index_backwards'] = range(len(reviews), 0, -1)
wine_reviews['index_backwards']
'''
0 129971
1 129970
...
129969 2
129970 1
Name: index_backwards, Length: 129971, dtype: int64
''''KAGGLE > Pandas' 카테고리의 다른 글
| [kaggle] Learn Tutorial_Pandas 정리_1 0 | 2022.11.23 |
|---|
