
yoooniverse
[kaggle] Learn Tutorial_Pandas 정리_2 본문
< 5 > Data Types and Missing Values
this is about) how to investigate data types within a DataFrame or Series
also going to learn about)how to find and replace entries.
Dtypes
What is Dtype? The data type for a column in a DataFrame or a Series
1. dtype, dtypes, astype
- dtypes: returns the dtype of every column in the DataFrame
- keep in mind) columns consisting entirely of strings do not get their own type; they are given the object type
reviews.price.dtype # dtype('float64')
reviews.dtypes #shows each coloumns' dtype
'''
country object
description object
designation object
points int64
price float64
province object
region_1 object
region_2 object
taster_name object
taster_twitter_handle object
title object
variety object
winery object
dtype: object
'''
- astype
: to convert a column of one type into another
reviews.points.astype('float64')
- even index of DataFrame or Series has its own dtype
reviews.index.dtype # dtype('int64')
Missing Data
NaN: "Not a Number", 'float64' dtype
1. pd.isnull
: to select NaN values
reviews[pd.isnull(reviews.country)] #find if 'country' value is NaN
2. pd.notnull
: to select not NaN values
reviews[pd.notnull(reviews.country)]
3. fillna
: Replacing missing values
reviews.region_2.fillna("Unknown")
4. replace"A", "B" // replace "A" to "B"
: Used at non-null value that we would like to replace
reviews.taster_twitter_handle.replace("@kerinokeefe", "@kerino")
< 6 > Renaming and Combining
Renaming
1.
1 rename(columns={'A': 'B'}) # column 이름 A를 B로 변경
: lets you change index names and/or column names
rename index or column values by specifying an index or column keyword parameter, respectively
reviews.rename(columns={'points': 'score'})
2 rename(index={0 : 'firstEntry', 1 : 'secondEntry'}) #row index 숫자를 문자열로 변경
reviews.rename(index={0:'firstEntry', 1:'secondEntry'})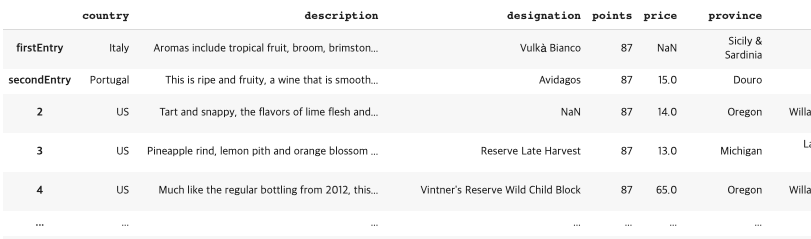
3 rename_axis("name_you_want", axis='rows or columns')
: Both the row index and the column index can have their own name attribute
reviews.rename_axis("fields", axis='columns').rename_axis("wines", axis='rows')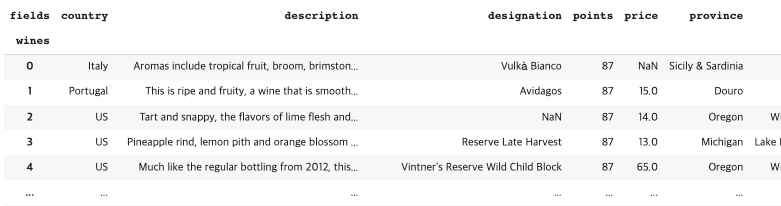
Combining
1. concat
: The simplest combining method
This is useful when we have data in different DataFrame or Series objects but have the same fields columns.
canadian_youtube = pd.read_csv("/content/drive/MyDrive/Kaggle/project0/CAvideos.csv")
british_youtube = pd.read_csv("/content/drive/MyDrive/Kaggle/project0/GBvideos.csv")
pd.concat([canadian_youtube, british_youtube])
2. join
: The middlemost combiner in terms of complexity
combine different DataFrame objects which have an index in common.
parameters
lsuffix : 중복된 column이 있을 경우 left DataFrame의 column명에 붙일 suffix
rsuffix : 중복된 column이 있을 경우 right DataFrame의 column명에 붙일 suffix
left = canadian_youtube.set_index(['title', 'trending_date'])
right = british_youtube.set_index(['title', 'trending_date'])
left.join(right, lsuffix='_CAN', rsuffix='_UK')